초록 — 정확하고 자동적인 다중 대상 탐지를 설계하는 것은 자율 주행 차량에게 어려운 문제이다. 이 문제를 해결하기 위해, 우리는 본 논문에서 최신 다중 모델 융합 프레임워크를 제안한다. 이 프레임워크는 탐지 성능을 향상시키기 위해 RGB 및 열적외선 카메라로부터 무료 정보를 제공한다. 이를 위해 먼저 관심 대상을 포함할 가능성이 있는 후보 제안을 추출하기 위해 각 입력 이미지에 대한 조밀한 단순 심층 모델로 레티나넷을 사용한다. 그런 다음, 모든 제안서는 두 가지 양식에서 얻은 제안을 연결하여 생성됩니다. 마지막으로, 중복 제안은 NMS(Non-Maximum Suppression)에 의해 제거된다. 핀란드 군도의 선박에 탑재된 센서 시스템에 의해 수집된 실제 해양 데이터 세트에 대해 제안된 프레임워크를 평가한다. 이 시스템은 자율 선박 개발에 사용되며, 운용 범위와 기후 조건에서 데이터를 기록한다. 실험 결과는 우리의 후기 융합 프레임워크가 중간 융합 및 유니모달 프레임워크에 비해 더 많은 탐지 정확도를 얻을 수 있음을 보여준다.
I. 소개
최근 몇 년 동안, 육상, 공중, 해상 중 어느 곳에서든 자율 주행 차량을 개발하려는 시도가 여러 차례 있었다. 신뢰할 수 있는 자율 주행 차량의 개발은 대상 감지 방법의 성능에 크게 의존한다. 최근 연구는 자율 차량 애플리케이션에서 표적 감지 및 센서 융합을 위한 심층 신경망의 잠재력을 보여준다. 대부분의 최첨단 표적 검출기는 슬라이딩 윈도우 또는 영역 제안 방법을 사용한 분류를 위해 컨볼루션 신경망(CNN)을 사용한다[1] [2] [3]. 이러한 검출기는 검출 정확도를 향상시키기 위해 신뢰할 수 있는 표적 제안을 추출할 수 있다. 또한 이미지 전체에 걸친 철저한 슬라이딩 윈도우 검색을 방지하여 슬라이딩 윈도우와 같은 고밀도 감지 접근 방식에 비해 계산 시간과 비용을 현저하게 줄인다. 가장 인기 있는 검출기 중 하나는 다양한 새로운 작업과 데이터 세트로 확장된 지역 기반 컨볼루션 신경망(R-CNN)[1]이다. 모든 제안을 CNN에 별도로 전달하기 때문에 계산 비용이 많이 들지만, Fast R-CNN[2]과 Fast R-CNN[3]은 심층 컨볼루션 신경망으로 더 낮은 계산 시간과 비용을 얻는다.
레티나넷[4]은 가능한 물체 제안의 고밀도 표본을 고속 RCNN보다 빠르고 간단한 방식으로 생성하는 한 단계 객체 감지기이다.
다중 센서 양식 융합은 자율 주행 차량에서 목표 감지를 정확하게 달성하기 위한 또 다른 솔루션이다. 단일 센서는 모든 가능한 조건에서 충분한 정보를 제공할 수 없으므로, 이질적인 센서 세트의 데이터를 결합하면 더 정확하고 신뢰할 수 있는 정보를 생성할 수 있다. 그러나 다양한 센서의 데이터를 결합하는 이상적인 접근 방식은 없다. 이러한 이유로, 우리는 본 논문에서 데이터 융합 수준이 목표 감지 정확도에 미치는 영향을 조사한다. 오늘날 많은 제품이 바다를 통해 운송되기 때문에, 신뢰할 수 있는 목표 탐지를 설계하는 것은 해상 안전을 위한 중요한 작업이다. 그러나 목표 탐지는 빛 반사, 카메라 움직임 및 조명 변화로 인해 해양 환경에서 어려운 문제이다 [5].
본 논문에서는 해양 환경의 대상을 감지하고 현지화하기 위한 최신 융합 프레임워크를 제시한다. 표적은 다양한 종류의 해양 선박과 항행 부표로 분류된다. 우리의 프레임워크는 RGB 카메라와 적외선(IR) 카메라의 정보를 결합하여 목표 감지 정확도를 향상시킨다. RGB 이미지는 인간의 시각적 인식에서 더 나은 구별 능력을 가지고 있다. 그러나 효과 음영과 조명 소음에 시달립니다. 반대로 열 IR 영상은 이러한 소음 효과에 덜 민감하고 야간에는 따뜻한 물체에 대한 추가 정보를 제공합니다 [6]. 따라서 이 두 가지 양식의 융합은 대상 탐지 문제를 해결하는 효과적인 솔루션을 제공한다.
우리의 프레임워크는 관심 대상 제안을 추출하기 위해 먼저 각 입력 카메라 이미지에 대해 별도로 레티나넷을 사용한다. 그런 다음, 두 카메라에서 얻은 목표 제안을 연결하고 가능한 제안의 최종 세트를 생성한다. 마지막으로, 최대가 아닌 억제 절차는 중복 제안(동일한 대상에 대한 중복 탐지)을 제거하기 위한 제안 집합에 적용된다. 핀란드 군도의 선박이 수집한 실제 센서 데이터로 실험을 실시한다. 데이터는 다른 환경 조건(기상 조건, 주간/야간)의 RGB 및 열 IR 카메라 이미지를 나타냅니다. 우리가 아는 한, 현재 해양 환경에서 목표 탐지를 위해 심층 CNN 기반 다중 모드 융합을 사용하는 것에 대한 기존 연구는 없다.
융합이 탐지 성능에 미치는 영향을 평가하기 위해, 우리는 융합 프레임워크를 검출에 RBG 또는 IR만 사용하는 두 개의 단일 프레임워크와 비교했다. 또한 데이터의 탐지 성능에 어느 수준의 융합이 더 효과적일 수 있는지를 찾기 위한 중간 융합 프레임워크를 제안했다. 실험 결과는 우리의 후기 융합 프레임워크가 최첨단 프레임워크에서 성능이 우수하다는 것을 보여준다.
그 논문의 나머지 부분은 다음과 같이 정리되어 있다. 섹션 II는 가장 중요한 관련 작업에 대해 논의합니다. 섹션 III는 레티나넷의 간략한 배경과 관련이 있다. 제안된 후기 융합 프레임워크는 섹션 IV에 소개된다. 실험 결과는 섹션 V에 제시되어 있다. 마지막으로, 결론은 섹션 VI에 제시된다.
II. 관련 작업
융합을 위한 CNN: 여러 센서의 정보를 융합하는 다양한 접근 방식이 있습니다. 일반적으로 이러한 접근 방식은 융합에 사용되는 데이터 추상화 수준에 기초하여 초기 융합, 중간 융합 및 후기 융합의 세 가지 주요 그룹으로 나눌 수 있다. 픽셀 레벨 융합이라고도 하는 초기 융합에서는 원시 센서 데이터가 결합되어 정보 추출 알고리즘을 적용하기 전에 융합 데이터를 생성한다. 예를 들어, [7]에서는 여러 출력 계층에서 표적 탐지를 수행하기 위해 픽셀 레벨 융합을 위한 심층 신경망이 제안된다.
형상 수준 융합이라고도 하는 중간 융합에서는 각 원시 데이터에서 추출된 형상이 융합된다. [8]에서는 자율 주행 차량의 객체 분류를 위해 LIDAR과 RBG 데이터를 결합하는 중간 융합 접근법이 제안된다. 이 접근 방식은 포인트 클라우드 데이터를 깊이 맵으로 변환한 다음 데이터를 CNN에 제공한다. 또 다른 연구에서는 딥 러닝 기반 융합 방법[9]이 두 소스 이미지의 모든 기능을 포함하는 융합 이미지를 생성한다. IR과 RGB. DenseFuse [10]은 RGB 및 IR 영상의 가장 깊은 특징을 중간 융합 방식으로 추출하고 보존하기 위한 또 다른 심층 네트워크 아키텍처이다. 인코더, 퓨전 및 디코더의 세 부분으로 구성됩니다.
의사결정 수준 융합이라고도 하는 후기 융합에서는 검출기를 각 센서에 독립적으로 적용한 후 그 결과를 결합하여 최종 검출을 한다. [5]에서는 4개 센서의 융합 검출 결과에 따라 객체 영역 제안을 생성하기 위한 확률적 데이터 연결 방법을 기반으로 한 최신 융합을 제안하였다.
표적 감지를 위한 CNN: 지난 몇 년 동안, 다양한 CNN 기반 표적 탐지기가 자율 주행 차량에 대해 제안되었다. 이러한 검출기의 대부분은 Fast R-CNN [2], Fast R-CNN [3], LetinaNet [4], You Only Look Once (YOLO) [11] 및 Single Shot Multibox Detector(SSD)[12]와 같은 CNN을 기반으로 구축되었다. 이러한 검출기는 1단계 검출기와 2단계 검출기의 두 가지 주요 그룹으로 나눌 수 있다. 2단계 검출기는 후보 대상 위치를 생성하는 데 외부 모듈을 활용할 때 일반적으로 1단계 검출기보다 속도가 느리다. 그러나 어려운 예제 고려 사항으로 인해 탐지 정확도가 더 높습니다. 모형이 잘 예측하지 못한 예가 하드 예제입니다. 이와는 대조적으로, 1단계 객체 감지기는 가능한 객체 제안의 고밀도 표본을 더 빠르고 간단한 방식으로 생성한다. [13]에서는 4개 센서의 정보 융합을 기반으로 관심 대상의 밀도 높은 제안을 찾는 접근 방식을 제시하였다.
III. 레티나넷
레티나넷[4]은 백본 네트워크와 두 개의 서브 네트워크를 포함하는 단순한 조밀 검출기이다. 첫째, 백본 네트워크는 전체 입력 이미지에 대한 컨볼루션 기능 맵을 계산한다. 그런 다음, 첫 번째 하위 네트워크는 백본의 출력에서 객체 분류를 수행하고 두 번째 하위 네트워크는 컨볼루션 경계 상자 회귀를 적용한다. 레티나넷의 백본 네트워크는 하향 경로와 횡방향 연결을 가진 단일 해상도 입력 이미지에서 풍부한 다중 스케일 피처 피라미드를 효율적으로 구성하기 위해 피처 피라미드 네트워크(FPN)[14]를 사용한다.
반면에, FPN은 심층 컨볼루션 네트워크의 피라미드 특징 계층을 고려하여 다중 스케일 객체를 나타낼 수 있다.
우리의 프레임워크에서, 융합된 이미지는 컨볼루션 커널을 통해 이미지를 처리하고 깊은 특징을 생성하는 잔차 네트워크(ResNet50 및 ResNet101) [15] 또는 VGG(Visual Geometry Group) 네트워크[16] 인코더에 입력으로 적용할 수 있다. 그런 다음 FPN을 적용하여 다양한 척도로 동일한 치수 형상을 추출한다. 그런 다음 이러한 피라미드 기능이 두 서브넷에 공급되어 개체를 분류하고 찾습니다. 또한, 레티나넷은 계층 불균형 문제를 해결하고 어려운 예제의 중요성을 높이기 위해 초점 손실을 제안했다.
IV. 제안된 후기 융합 프레임워크
A. 작업 흐름
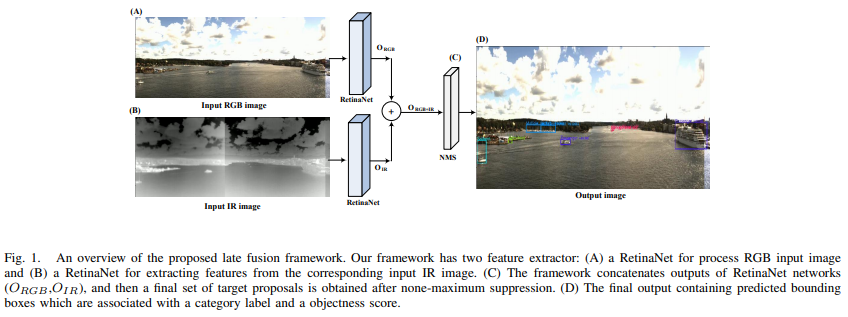
다중 모델 융합 프레임워크의 제안된 워크플로는 그림 1에 설명되어 있다. 프레임워크는 먼저 RGB 및 IR 카메라를 사용하여 선박을 둘러싼 환경에 대한 자세한 설명을 학습하고 얻는다. 그런 다음 별도의 레티나넷 네트워크를 사용하여 각 입력 카메라 이미지를 독립적으로 처리하고 이미지에서 기능 변환을 학습한다. 이 프로세스에는 상단 왼쪽 모서리의 좌표(x, y), 너비 및 높이 h를 사용하여 이미지에서 대상의 위치 지정을 나타내는 경계 상자 제안의 추정이 포함된다. 또한 각 상자에는 레이블 및 객체성 점수가 있다. 그 후, 두 가지 모달리티(ORGB 및 OIR)의 출력 경계 상자가 연결되어 가능한 모든 대상 경계 상자를 생성한다. 마지막으로, NMS(Non Maximum Suppression)는 최종 상자를 생성하고 중복 탐지를 제거하기 위해 모든 상자(ORGB+ OIR)에 적용됩니다. NMS는 많은 표적 탐지 접근법에서 후처리를 위한 인기 있는 방법이다 [1] [2] [3]. 우리의 프레임워크는 다음과 같은 두 센서에서 예측된 모든 상자에 NMS를 적용했다.
(1) 먼저 점수 값이 0.6보다 낮은 예측 상자를 모두 폐기한다. 그런 다음, 나머지 후보 중에서 점수 값이 가장 큰 상자를 정확한 예측 상자 best로 가정한다(그림 2(A)).
(2) 마지막으로, IoU(Intersection over Union)가 bbest(그림 2(B))와 α보다 낮은 나머지 상자를 제거합니다. 각 박스 bi는 다음 함수에 따라 best에 의해 겹치는 경우 최종 박스로 가정한다.

B. 구현 세부 정보
레티나넷의 백본 및 초점 손실에 대한 다양한 설정을 조사한다. 레이어의 수는 레티나넷의 백본의 종류에 따라 달라진다. 백본이 ResNet50 또는 ResNet101인 경우 레이어의 수는 각각 50과 101이다. VGG19에는 19개의 레이어가 있습니다.
Adam 최적화는 학습 속도 0.00001 및 감소 계수 0.1로 모델을 훈련시키는 데 사용된다. 네트워크의 다른 하이퍼 파라미터는 다음과 같다. 앵커는 IoU 임계값이 0.5인 지상 실측 객체 박스에 할당된다. 우리는 FPN에서 다양한 수의 스케일 및 가로 세로 비율 앵커를 테스트한다. 우리는 4개의 하위 옥타브 척도(1, 1.2, 1.6)와 4개의 가로 세로 비율[0.5, 1, 2, 3]에 걸친 위치당 단일 사각 앵커에서 12개의 앵커까지의 사례를 고려한다. 각 시대의 반복 횟수는 20회, 반복 횟수는 1000회였다. 두 가지 손실이 계산되었다: 초점 손실이 있는 분류 손실과 부드러운 L1이 있는 회귀 손실이 계산되었다. 우수한 기능 표현을 배우기 위해 ImageNet [17]에서 레티나넷을 사전 교육한다. 그리고 나서, 그들은 우리의 데이터를 정밀하게 조정한다. 프레임워크를 훈련하고 테스트하기 위해, 우리는 해양에서 서로 다른 위치와 대상을 나타내는 다양한 소스 비디오를 활용한다.

V. 실험 설정 및 결과
A. 데이터 설명
핀란드 군도의 선박에 장착된 센서 시스템을 사용하여 데이터를 수집했다. 이 센서 시스템은 RGB(가시 스펙트럼)와 IR(열) 카메라 어레이를 포함하며, 출력을 동기화하고 연결하여 파노라마 이미지를 형성할 수 있습니다. 보이는 각각의 카메라는 풀 HD 해상도를 가지고 있고 열 카메라는 VGA 해상도를 가지고 있다. 두 카메라 유형 모두 수평 시야가 약 35도입니다. 이 센서 세트는 데이터를 지속적으로 수집하여 다양한 환경 및 지리적 시나리오에서 데이터를 제공합니다. 이 센서 세트의 영상 정렬 등록 파라미터는 보정 영상에서 해당 기능을 수동으로 찾고 선형 불일치를 최소화하여 결정되었습니다. 이 데이터는 해양 선박(선박과 보트)과 항해 부표 등 다양한 표적을 가진 해양 시나리오를 보여준다. 실험을 위해 프레임워크 훈련 및 테스트를 위해 각각 7250 및 1750 IR/RGB 쌍 이미지를 선택했다. 훈련 영상과 테스트 영상을 생성하기 위한 소스 영상은 다릅니다. 데이터 샘플의 IR/RGB 쌍은 그림 1에 나와 있습니다. 각 이미지의 원래 크기는 3240 x 944 픽셀입니다. 레티나넷 훈련의 계산 시간을 줄이기 위해, 우리는 원본 영상의 크기를 1200 × 400 픽셀로 조정했다. 데이터 세트의 6개 객체 범주(선박 5종, 항법 부표)에 대한 경계 상자와 레이블에 수동으로 주석을 달았다. 표 I은 각 카메라에 대한 훈련 및 테스트 데이터 세트의 클래스 분포를 보여준다. "승객선", "모터보트", "선박선" 또는 "도크선"으로 시각적으로 인식될 수 없는 멀리 있는 선박은 일반 라벨 "선박" 아래에 배치되었다.
훈련 영상은 레티나넷 훈련을 위해 여러 무작위 변환을 통해 증강된다. 회전, 자르기, 회전, 회전, 수직 플립 및 수평 플립을 포함한 임의의 변환이 영상에 적용되었습니다. 이러한 종류의 데이터 확대는 이전 연구에서 널리 사용되어 왔다 [13][5].
B. 표적 탐지 프레임워크의 비교
핵융합이 검출 성능에 미치는 영향을 평가하기 위해, 우리는 후기 융합 프레임워크를 세 가지 프레임워크에 비교한다. (1) RGB 기반 검출기는 검출을 위해 RGB 영상만 활용하고 (2) IR 기반 검출기는 검출을 위해 IR 영상만 활용하고 (3) 중간 융합 프레임워크는 검출에 RGB 영상과 IR 영상 모두를 활용한다. 중간 융합 프레임워크에서 먼저 두 개의 RGB 및 IR 영상의 획득한 기능을 추출한 다음 두 가지 인기 있는 딥 러닝 기반 접근 방식(DLF [9] 및 DenseFuse [10])을 사용하여 융합된다. 그 후 획득된 퓨전 영상에 대상 검출을 수행하기 위해 레티나넷을 적용한다. 우리는 또한 레티나넷의 세 가지 다른 백본에 대한 결과를 제공한다.

4개의 제안된 프레임워크는 평균 정밀도 백분율(%AP)을 사용하여 테스트 데이터 세트에서 비교된다. 이는 목표 탐지에 대한 실제 메트릭이기 때문이다. 표 II에는 각 5개의 선박 등급과 항법 부표에 대한 AP가 나와 있습니다. 표 II에서 세 가지 관찰 결과가 나왔습니다. 첫째, 최신 융합 프레임워크는 대상이 1010픽셀 이상의 영역을 점유할 때 다른 세 가지 프레임워크보다 높은 정확도를 달성할 수 있다. 그렇지 않으면, DLF를 기반으로 하는 중간 융합 프레임워크는 작은 대상에 대한 최신 융합보다 높은 정확도를 달성할 수 있다. 일반적으로 "선박"과 "항행 부표"에 속하는 작은 대상을 탐지하는 것은 관련 정보가 적기 때문에 중형 및 대형 물체보다 더 어렵다. 제안된 중간 융합 프레임워크는 데이터 세트에서 두 개의 입력 이미지를 처음 융합했기 때문에 이러한 대상 범주에 대해 더 많은 상황 정보를 제공할 수 있다. RGB 영상과 IR 영상을 기반으로 하는 두 개의 유니모달 프레임워크는 클래스 "Passenger vessel"에 대해 각각 65.4%, 61.7%의 최고 정확도를 얻을 수 있다. 결과는 우리의 최신 융합 프레임워크가 "승객선"에 대해 84.6%를 얻을 수 있다는 것을 보여준다. 또한 "Motorboat", "Sailboat", "Docked vessel"의 정확도가 다른 세 가지 프레임워크와 비교했을 때 더 높다. 그러나 DLF를 기반으로 하는 중간 융합 프레임워크는 후기 융합보다 두 종류의 작은 대상인 "Vessel"과 "Navigation booy"에 대해 65.4%, 61.7%의 높은 정확도를 달성할 수 있다. 둘째, 결과는 다중 모델 프레임워크가 다중 모델 프레임워크와 단일 모델 프레임워크 간의 비교에서 더 나은 결과를 얻을 수 있음을 보여준다. 다중 모델 프레임워크는 IR 및 RGB 이미지의 정보를 결합하여 더 풍부한 기능을 학습할 수 있기 때문이다. 셋째, 백본 VGG19를 사용하는 레티나넷은 다른 두 백본 ResNet50과 ResNet101보다 더 정확한 성능을 발휘한다.
C. 이미지 융합 접근법의 비교
중간 융합 프레임워크에서는 먼저 이미지 융합 접근 방식을 사용하여 두 개의 RGB 및 IR 이미지를 융합한다. 그런 다음 획득된 퓨전 영상에 검출을 위해 레티나넷을 적용합니다. 다음 6가지 공통 품질 메트릭을 사용하여 테스트 데이터 세트의 중간 융합 프레임워크에서 제안된 두 가지 심층 네트워크 기반 이미지 융합 접근법(DLF [9] 및 DenseFuse [10])의 성능을 평가했다 ; 구조적 유사성(SSIM) [18], 특징 상호 정보 웨이블릿(FMIW) [19], 특징 상호 정보 이산 코사인(FMIdct), 엔트로피(EN), 품질(QAB/F) [20], 소음(NAB/F) 및 상관관계의 합계
그림.3은 DLF 및 DenseFuse에 의해 야기된 융합 1750 테스트 이미지에 대한 메트릭의 평균 값을 보여준다. 결과는 SSIM, FMIw 및 FMIdct 값이 가장 높은 DLF 융합 방법이 DenseFuse보다 성능이 우수하다는 것을 나타낸다. 또한 DLF의 SCD 값은 DenseFuse 방법보다 작습니다. 그 이유는 DLF가 더 많은 구조적 정보와 특징을 추출할 수 있기 때문이다. 그러나 DenseFuse는 NAB/F, QAB/F, En의 값이 가장 낮기 때문에 더 많은 자연성을 얻고 덜 인공적인 노이즈를 포함합니다. 일반적으로 DLF는 제안된 중간 융합 프레임워크에서 대상 탐지에 대해 DenseFuse보다 성능이 우수하다.
D. 질적 결과
그림 4 (A)와 (B)는 제안된 RGB 기반 검출기와 IR 기반 검출기의 테스트 데이터 세트의 예에 대한 검출 결과를 설명한다. 또한 이미지 융합 접근법으로 DenseFuse와 DLF를 사용할 때 중간 융합 프레임워크의 탐지는 각각 그림 4 (C)와 (D)에 나와 있다. 그림 4(E)에서 제안된 후기 융합 프레임워크의 탐지 결과는 이 프레임워크가 다른 제안된 프레임워크보다 더 효율적인 대상을 감지할 수 있음을 보여준다. 왜냐하면 후기 융합 프레임워크는 각 입력 이미지에서 RetinaNet에 의해 추출된 다른 기능 맵의 정보를 통합할 수 있기 때문이다. 그러나 DLF 기반 중간 융합 프레임워크는 처음에 이러한 이미지를 융합하여 두 이미지의 보완 정보를 활용했기 때문에 후기 융합 프레임워크보다 작은 대상을 정확하게 감지할 수 있다.
VI. 결론
본 논문에서는 실제 해양 데이터에서 다중 표적 탐지를 위한 최신 융합 프레임워크를 제시한다. 우리의 프레임워크는 IR 및 RGB 이미지의 장점을 모두 활용한다. 영역 제안을 추출하기 위해 각 입력 영상에 별도로 레티나넷을 적용한다. 그런 다음 각 촬영장비에서 얻은 제안서를 결합하여 최종 탐지 결과를 생성한다. 실제 해양 데이터에 대한 실험 결과는 우리의 후기 융합 프레임워크가 두 개의 유니모달 프레임워크와 두 개의 중간 융합 프레임워크로 더 높은 감지 정확도 비교를 달성할 수 있음을 보여준다. 우리의 프레임워크는 물체를 감지하고 실제 해양에서 선박 유형 또는 항법 부표 중 하나로 효과적으로 분류할 수 있다.
Acknowledgement
컴퓨팅 리소스는 핀란드 에스푸의 CSC-IT 과학 센터에서 제공하였다.






REFERENCES
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell., 38(1):142–158, 2016.
[2] R. Girshick. Fast r-cnn. In IEEE International Conference on Computer Vision (ICCV), pages 1440–1448, 2015.
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards realtime object detection with region proposal networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 91–99. Curran Associates, Inc., 2015.
[4] T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar. Focal loss for ´ dense object detection. In IEEE International Conference on Computer Vision (ICCV), pages 2999–3007, 2017.
[5] M. Haghbayan, F. Farahnakian, J. Poikonen, M. Laurinen, P. Nevalainen, J. Plosila, and J. Heikkonen. An efficient multi-sensor fusion approach for object detection in maritime environments. In 21st International Conference on Intelligent Transportation Systems (ITSC), pages 2163–2170, 2018.
[6] Y. Yan, J. Ren, H. Zhao, J. Zheng, Ezrinda M.Z., and J. Soraghan. Fusion of thermal and visible imagery for effective detection and tracking of salient objects in videos. volume 9917, pages 697–704, 2016.
[7] C. Zhaowei, F. Quanfu, Schmidt F. Rogerio, and V. Nuno. A unified ´ multi-scale deep convolutional neural network for fast object detection. CoRR, abs/1607.07155, 2016.
[8] G. Hongbo, B. Cheng, J. Wang, K. Li, J. Zhao, and D. Li. Object classification using cnn-based fusion of vision and lidar in autonomous vehicle environment. pages 1–1, 04 2018.
[9] H. Li, X.J Wu, and J. Kittler. Infrared and visible image fusion using a deep learning framework. CoRR, 2018.
[10] H. Li and X.Jun Wu. Densefuse: A fusion approach to infrared and visible images. CoRR, 2018.
[11] J.Redmon and A. Farhadi. Yolov3: An incremental improvement. CoRR, abs/1804.02767, 2018.
[12] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, and A. C. Fu, C.and Berg. Ssd: Single shot multibox detector, 2015. cite arxiv:1512.02325Comment: ECCV 2016.
[13] F. Farahnakian, M. Haghbayan, J. Poikonen, M. Laurinen, P. Nevalainen, and J. Heikkonen. Object detection based on multisensor proposal fusion in maritime environment. In 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 971–976, 12 2018.
[14] T. Lin, P. Dollar, R.B. Girshick, K. He, B. Hariharan, and S.J. ´ Belongie. Feature pyramid networks for object detection. In IEEE Conference on Computer Vision and Pattern Recognition, pages 936– 944, 2017.
[15] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015.
[16] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
[17] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
[18] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004.
[19] M. Haghighat and M. A. Razian. Fast-fmi: Non-reference image fusion metric. In 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), pages 1–3, Oct 2014.
[20] C. S. Xydeas and V. Petrovic. Objective image fusion performance measure. Electronics Letters, 36(4):308–309, Feb 2000.
[21] V. Aslantas and E. Bendes. A new image quality metric for image fusion: The sum of the correlations of differences. AEU - International Journal of Electronics and Communications, 69(12):1890 – 1896, 2015.
'프로그래밍 > 논문 번역' 카테고리의 다른 글
| MU-Net: Deep Learning-based Thermal IR Image Estimation from RGB Image 번역 (0) | 2021.05.12 |
|---|---|
| 논문 번역 AUTOMATIC PARKING OF SELF-DRIVING CAR BASED ON LIDAR (0) | 2021.05.06 |


댓글