지난 시간에 RNN을 배워보았습니다. RNN의 경우 Gradient Vanishing 문제가 발생했죠.
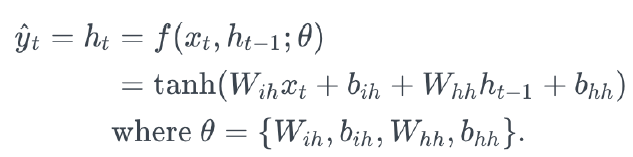
이유는 출력할 때 hyperbolic Tangent(하이퍼볼릭 탄젠트, tanh)으로 Back Propagation을 할 때 문제가 생기죠.

Back Propagation을 할 때 Tanh를 미분한 값을 곱하게 됩니다. 이 때 보시면 Tanh의 미분한 값은 1보다 작은 값이죠. 그래서 값이 점점 작아지게 됩니다. Gradient Vanishing 문제가 생기죠. 그래서 나온 기법이 LSTM(Long Short Term Memory)입니다.

상기 그래프는 LSTM 구조를 나타내고 있는데요. 보시면 input, forget, output 등의 sigmoid 함수가 들어가 있습니다.

파란색 그래프가 sigmoid 함수입니다. 함수를 보시면 아시겠지만 sigmoid 함수는 0에서 1사이의 값을 가지고 있습니다. 즉, sigmoid 함수가 게이트(문)가 되는 겁니다. 가지고 있는 값을 어느정도 통과시킬지 결정하는 게이트말이죠. 그래서 input과 output, forget 게이트라는 걸 만들어서 각 데이터에 대한 유효한 값을 결정해줍니다.
그리고 c라는 기억 셀(cell state)이 있습니다. 이전의 데이터 중에서 기억할 건 기억하고, 뺄 건 빼서 최종 출력 값을 생성하는 시점에 도와준다고 합니다.

그리고 GRU(Gated Recurrent Unit)입니다. LSTM이 복잡해서 뉴욕대학교의 조경현 교수님이 발명하셨다고 합니다. 그러나, 실제로는 LSTM을 더 많이 쓴다고 합니다(오픈소스가 LSTM이 많아서)
RNN 대비해서 LSTM이 기억력은 더 좋아졌지만, 더 복잡하기 때문에 더 많은 학습데이터와 학습시간이 필요하다고 합니다. 그리고 완벽하게 긴 데이터를 기억할 수 있게 된 것은 아닙니다. 한계가 존재하고, 보통 Time step으로 100? 정도까지 LSTM을 사용한다고 하네요. 그리고 층수로는 4층정도 까지 사용하라고 구글에서 권장했다고 합니다. 참고하시기 바랍니다.
[출처] 김기현의 딥러닝을 활용한 자연어처리 입문
'프로그래밍 > 김기현의 딥러닝을 활용한 자연어처리 입문과정' 카테고리의 다른 글
| RNN이 쓰이는 어플리케이션(분야)은 어떤게 있을까? (0) | 2020.07.03 |
|---|---|
| Vanilla RNN(Recurrent Neural Network)이란? (0) | 2020.07.02 |
| Maximum Likelihood Estimation(MLE)과 Cross Entropy(CE)와의 관계. 결국 같은것이었다. (0) | 2020.07.01 |
| Maximum Likelihood Estimation(MLE)를 프로그래밍에 적용하는 방법. Negative Log Likelihood(NLL) (0) | 2020.06.30 |
| Maximum'Likelihood'Estimation 란? (0) | 2020.06.29 |




댓글