728x90
반응형
확률 표현에서 다음은 모두 같은 식이다. 여기서 세타는 랜덤 변수(Random Variable)이다.

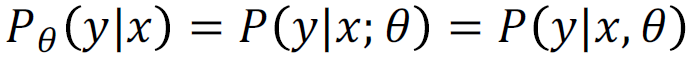
MLE의 목표는 우리가 확률 분포로 부터 샘플링하여 데이터를 넣었을 때, 확률 분포를 반환하는 가상의 함수를 모사하는 것이다. 그래서 우리는 가상의 확률분포를 모사하는 확률분포 파라미터 세타값을 찾는 것이 목표이다.
이걸 딥 뉴럴 네트워크에 대입하면 다음과 같이 가중치 W와 편향 b를 찾는 것이 된다.

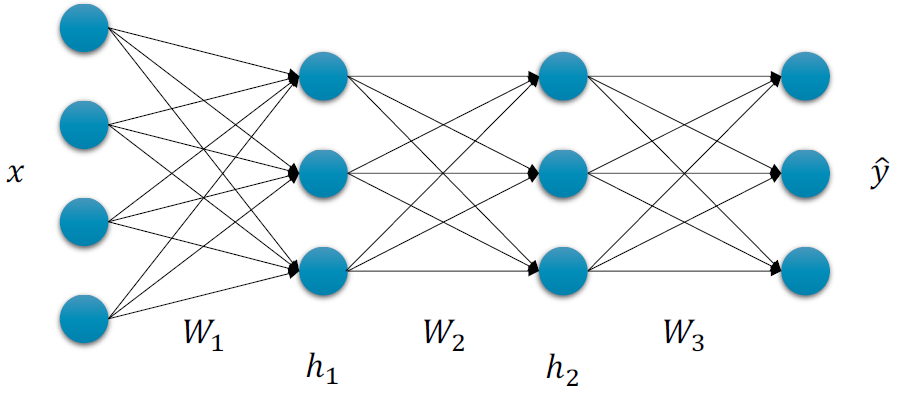
여기서 문제는 이걸 찾기 위해 적용되는 기법은 Gradient Ascent라는 것이다. 그러나, 프로그래밍에서는 보통 Gradient Descent를 지원한다. 그렇기에 우리는 MLE에 마이너스(-)를 붙여서 Negative Log Likelihood(NLL)로 표현한다. 그리고 마이너스가 붙음으로써 Maximize(최대화) 문제에서 Minimize(최소화) 문제로 바뀌게 된다. 다음은 이 NLL을 수식으로 표현한 것이다.

Gradient Descent를 수행하기 위해 파라미터에서는 미분이 필요한데, 이를 수행하기 위해 back-propagation을 활용한다.
[출처] 김기현의 딥러닝을 활용한 자연어처리 입문
728x90
반응형
'프로그래밍 > 김기현의 딥러닝을 활용한 자연어처리 입문과정' 카테고리의 다른 글
| RNN의 Gradient 문제 해결하기 위한 기법? LSTM(Long Short Term Memory)와 GRU(Gated Recurrent Unit)이란? (0) | 2020.07.04 |
|---|---|
| RNN이 쓰이는 어플리케이션(분야)은 어떤게 있을까? (0) | 2020.07.03 |
| Vanilla RNN(Recurrent Neural Network)이란? (0) | 2020.07.02 |
| Maximum Likelihood Estimation(MLE)과 Cross Entropy(CE)와의 관계. 결국 같은것이었다. (0) | 2020.07.01 |
| Maximum'Likelihood'Estimation 란? (0) | 2020.06.29 |




댓글