Maximum Likelihood Estimation란 어떤 확률분포(매개변수)의 가능성을 최대화 시켜주는 것입니다. 수식으로만 설명드리면 아마 이해가 안가실 겁니다. 그래서, 예를 한번 들어보겠습니다.
대한민국 신장 분포를 알고 싶다고 가정을 해봅니다. 아마 분포를 정확하게 아는 것은 신 뿐이겠죠?
대부분의 분포는 가우시안 분포를 따를겁니다. 평균이 얼마고 표준편차가 얼마다. 다들 중,고등학교 때 다 배우셨죠(?)
그래프는 다음과 같이 생겼습니다. 10명을 샘플로 추출해봤다고 가정 해볼게요. 여기서 가로축은 신장이구요 세로축은 사람 수입니다.
밑에 2개의 그래프는 중간점이 아닌 한쪽으로 치우친 분포를 보입니다.
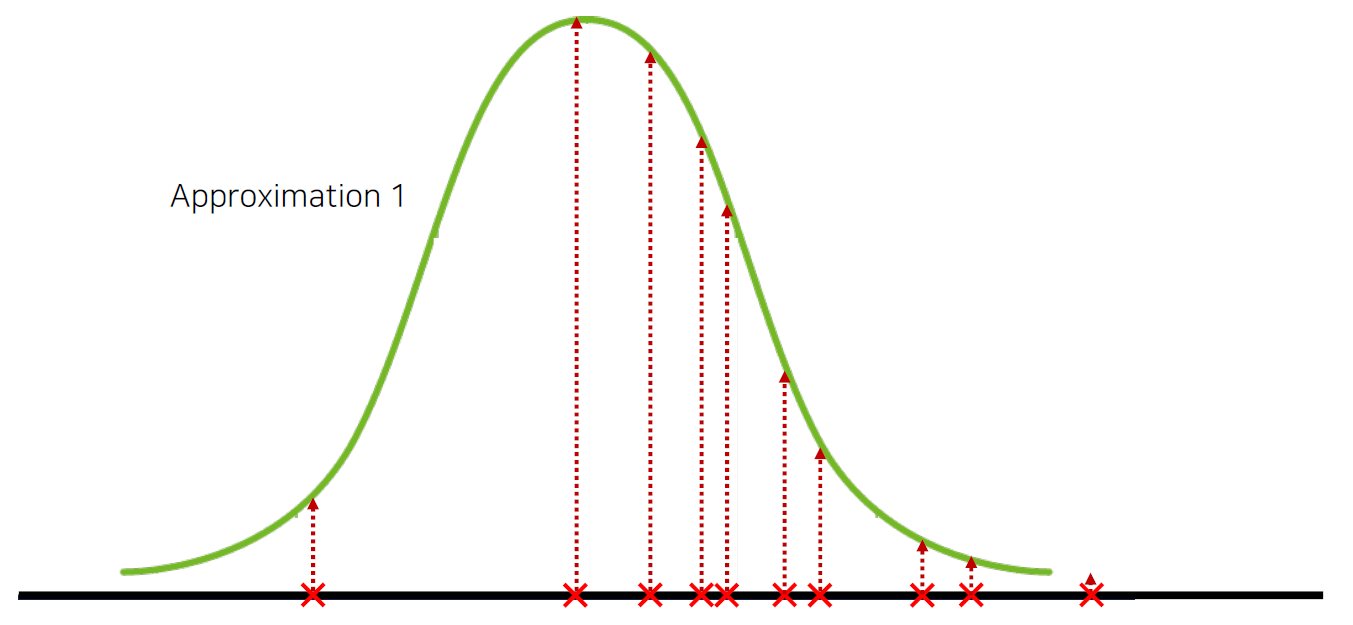
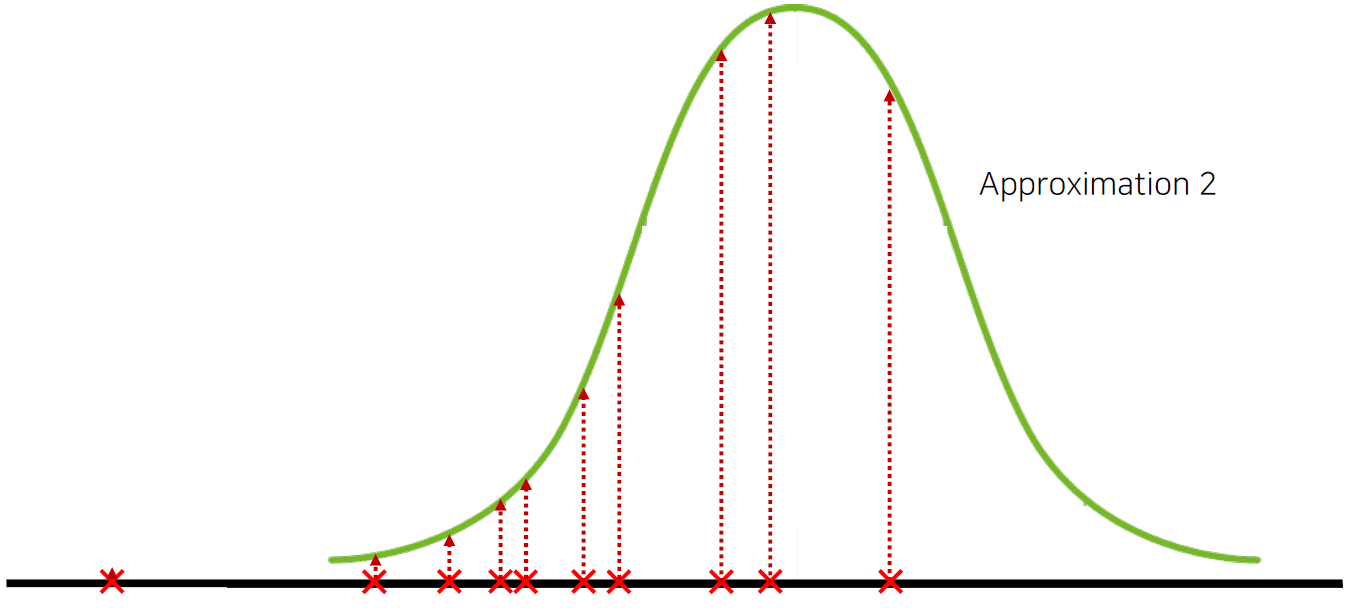
그리고 세번째 그래프에서는 중심점에 가깝에 분포를 많이했죠? 그러니깐, 즉 이전 2개의 그래프보다 데이터가 훨씬 많아졌죠?

첫번째 두번째 그래프보다 세번째 그래프로 우리나라 사람들의 신장분포를 더 잘 설명할 수 있을 겁니다. 왜냐면, 출력 데이터가 많기 때문이에요. 그러면 저 출력 데이터가 많은 곳, 즉 우리나라 사람의 수가 많은 곳에 우리나라 사람의 신장분포가 몰려있다라고 설명할 수 있겠죠?
반대로 출력 데이터가 적으면, 우리나라 사람들의 키가 어디에 주로 분포했는지 알 수가 없겠죠.
그래서 데이터가 확률분포에서 높은 확률분포를 갖는 입력 값을 찾는 게 Maximum Likelihood Estimation입니다. 식으로는 다음과 같이 표현됩니다.

왼쪽식이 Maximum Likelihood Estimation인데요. 오른쪽 식으로 변경을 하였습니다.
곱셈을 덧셈으로 변경한 것은, 컴퓨터 연산처리 측면에서 굉장한 이득을 줍니다. 컴퓨터는 곱셈연산이 불가합니다. 그래서 결국 곱셈횟수만큼 더해주게 되거든요. 특히, 파라미터가 많으면 많을 수록 점점 더 속도차이가 많이 납니다.
주사위 던진 횟수를 예로 들어서 계산을 해보겠습니다.

이런 확률을 가진 주사위가 있다고 가정하구요. 임의의 확률 분포를 2개씩 만들어보겠습니다.

첫번째 확률분포인 세타1, 그리고 두번째 확률분포인 세타2일 때 추정값을 구해봤구요.

세번째 확률분포인 세타3일 때 추정 값을 구해봤습니다. 세타3일 때의 계산 값이 가장크죠? 이걸 구하는 것이 Maximum Likelihood Estimation입니다. 이 Maximum Likelihood Estimation이 되는 입력 파라미터 값을 찾으면 그 상황에 대한 확률분포를 가장 잘 설명한다고 얘기할 수 있겠습니다.
[출처] 김기현의 딥러닝을 활용한 자연어처리 입문과정
'프로그래밍 > 김기현의 딥러닝을 활용한 자연어처리 입문과정' 카테고리의 다른 글
| RNN의 Gradient 문제 해결하기 위한 기법? LSTM(Long Short Term Memory)와 GRU(Gated Recurrent Unit)이란? (0) | 2020.07.04 |
|---|---|
| RNN이 쓰이는 어플리케이션(분야)은 어떤게 있을까? (0) | 2020.07.03 |
| Vanilla RNN(Recurrent Neural Network)이란? (0) | 2020.07.02 |
| Maximum Likelihood Estimation(MLE)과 Cross Entropy(CE)와의 관계. 결국 같은것이었다. (0) | 2020.07.01 |
| Maximum Likelihood Estimation(MLE)를 프로그래밍에 적용하는 방법. Negative Log Likelihood(NLL) (0) | 2020.06.30 |




댓글